


nicooprat
-
Posts
5 -
Joined
-
Last visited
-
Days Won
1
Content Type
Blogs
Gallery
Downloads
Events
Profiles
Forums
Articles
Media Demo
Posts posted by nicooprat
-
-
On 12/27/2018 at 9:45 PM, dkgrieshammer said:
Just a hint to fix the language issue; adding a check if a paramter was given helps in tesseract 4; remember that the language attributes are a little weird (eng for english, deu for german etc.) thanks a lot for the script
export PATH=/usr/local/bin/:$PATH screencapture -i /tmp/ocr_snapshot.png if [{query} = ""]; then tesseract /tmp/ocr_snapshot.png stdout 2>&1 else tesseract /tmp/ocr_snapshot.png stdout -l {query} 2>&1 fi
Thanks, merged your pull request but it looks like it just deleted the workflow file. Uploaded a new one with your code, works great!
On 12/27/2018 at 9:55 PM, deanishe said:ISO 639-2 or ISO 639-3 perhaps?
I don't know, but the full list of supported languages by Tesseract is here: https://github.com/tesseract-ocr/tesseract/blob/b67ea2c1a70c56053e142a5fb7cc18fb29cdc4b8/src/training/language-specific.sh#L21
-
On 12/15/2018 at 3:43 PM, ReinaSuo said:
I tried the solution No.3. Thanks for sharing. btw I am wondering if it is normal to have "warning" in clipboard.

It's very useful for me while recognizing English now. How can I make this work with Chinese?
The warning is certainly because you're taking the screenshot on a different monitor than your main one. Can't find anything in Tesseract to avoid this... Simplest workaround is to drag your app window to your main monitor and take the screenshot from there. Results should be much better!
By default, Tesseract try to guess language from results, so I guess it should work as is. In the last version of my Alfred script (see https://github.com/nicooprat/alfred-ocr/blob/master/README.md#usage), you can type "OCR [lang]" where "[lang]" is in this list: https://github.com/tesseract-ocr/tesseract/blob/b67ea2c1a70c56053e142a5fb7cc18fb29cdc4b8/src/training/language-specific.sh#L21
On 12/15/2018 at 5:11 PM, ReinaSuo said:I tried `brew install tesseract --with-all-languages` again.😭
Here is what I got:
Error: An exception occurred within a child process: Errno::ENOENT: No such file or directory @ rb_sysopen -I can't help with this one, you should seek help on the Tesseract project: https://github.com/tesseract-ocr/tesseract/issues
-
I recently added the `lang` parameter with `-l` flag:
tesseract /tmp/ocr_snapshot.png stdout -l {query} 2>&1It should allow you to run the command with `OCR fra` for french for example, but it should still work without any parameter. Tried just now and it works (Mac High Sierra & tesseract 3.05.01).
Possible solutions:
* add a way in the bash script to remove `-l` flag if `{query}` is undefined (don't know how to do this)
* downgrade to tesseract 3 as it seems to behave differently in 4
* remove this part in the bash script if you don't need it (see screenshot attached)
Hope it helps.

-
Hi there,
Just sharing my first workflow. Some OCR workflow already exist but are relying on some obscur chinese API with exposed personal credentials... This one use your system own installation of `tesseract`. Just take a snapshot and paste the text. The script usually takes no more than a few seconds.
https://github.com/nicooprat/alfred-ocr
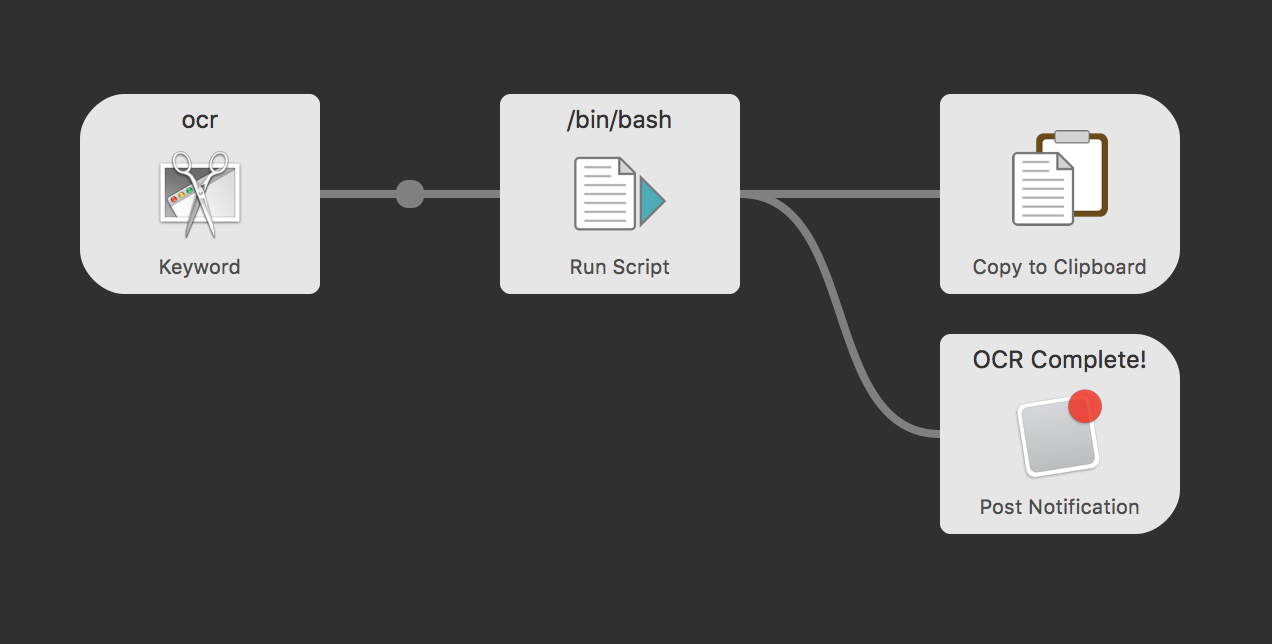
PR welcome.
Hope it helps!
- cands, Mike Outram, JJJJ and 3 others
-
 6
6



OCR: extract text from snapshot
in Share your Workflows
Posted · Edited by nicooprat
Someone got this error: `Processing output of 'output.notification' with arg 'read_params_file: Can't open stdout Tesseract Open Source OCR Engine v4.0.0 with Leptonica`. I have no clue what's happening, maybe someone could help here: https://github.com/nicooprat/alfred-ocr/issues/3.
Edit: solved, see Github issue.