


jmjeong
-
Posts
86 -
Joined
-
Last visited
-
Days Won
6
Content Type
Blogs
Gallery
Downloads
Events
Profiles
Forums
Articles
Media Demo
Posts posted by jmjeong
-
-
v2.1 has been released.
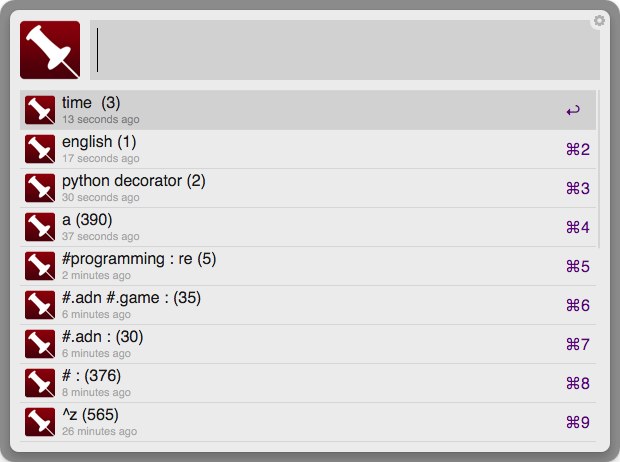
- multiple tag search : specify tag group for searching (#)- display last modified time of local cached bookmarks- display host name only in main list- display tag information in main list too- update the number of entries in the history list after searching- display untagged bookmarks in tag list- support sort option : title ascending(`^a`), title descending(`^z`), time ascending(`^d`), time descending(default)
-
Why do you need to get notes? They're also contained in the posts data.
If you add a description in note, note data is replaced with description in posts data. I need full text search for notes data.
Asides from notes data, updated bookmark can only be gotten in second launch anyway in my example.
-
Exactly. When the workflow is run, it loads the data from its cache. If there is no cached data, or it's older than 10 minutes (for example), it downloads the latest data in the background.
This approach has one significant drawback.
When I launch alfred-pinboard 20 minutes later from the last run, I got the old cache. Only after the background job is finished, I can get the fresh data. Updating bookmark is instant but updating notes can takes more time because of API request limit.
-
I think we're talking at cross purposes. The script I liked to does not call the API every time the workflow is run, nor would that be a good idea. It loads the data from the cache and updates the cache in the background if it's older than 5/10/whatever minutes.
Do you want that alfred-pinboard workflow invokes pinboard-download.py script in the background if cache is older than specified time?
It'd make sense to only grab bookmarks updated after you last hit the API, but the documentation isn't clear: the "all posts" endpoint accepts a fromdtparameter, but it says posts created after this time. What about updated posts?It is unclear. It needs test.
-
I'm aware of the API limits.
4 times an hour is not a huge deal, but it's 4 times an hour, every hour of every day, which is at least 10 time more than necessary. Also, a lot of people have several thousand bookmarks, so it takes a bit longer than a second for them. If a few hundred people install the workflow, that's several gigabytes of unnecessary traffic per day for Pinboard…
The demo workflow I referenced won't call more often than every 5 or 10 minutes (it's configurable). With regard to the 3 second interval, you have to cache the time of your last request in any case, as it's possible for someone to call the workflow repeatedly within the 3/60/300 second limits.
Installing pinboard-download.py script is optional, and download duration is also configurable.
I use alfred-pinboard more than 10-20 times per hour. I think current approach does inflict less burden than calling server per each alfred-invocation. And I need fast search speed.
With regard to traffic issue, current pinboard-download.py could be updated for downloading the updated part only.
In my case, 500 bookmarks is only 68k, so traffic is not big issue for the time being.
-
By the way, why not an Add to Pinboard function?
I add URL to pinboard only from safari bookmarklet, not from alfred. Add to pinboard from alfred is time-consuming.
-
-
When I type "pbtag", select a tag, and hit return, I get the same message that Jono got in your thread for version 1:
Hit 'Tab' instead of 'return'. tag will be auto completed.
-
Good work!
A possibly useful tip regarding updating without having to do it manually or every X minutes via cron, but still keeping the responsiveness 1a:
What I do in such situations is check the age of the cached data, and fork a background process to do the update if it's stale. Here's a simple example that downloads Pinboard bookmarks (it's the tutorial for my Python workflow library), and the relevant code for forking background processes is here.
I think it's a much more elegant solution. No need to hit the Pinboard server every 15 minutes, the user doesn't need to faff around with cron or manual reloading, and the workflow remains instantly responsive as long as there's data in the cache.
I considered this option, too. But I decided the current method because of limits of API requests and fast speed of API.
In my test case, it(posts/all) takes less than 1 seconds with 500 or more bookmarks and the data in pinboard site is not frequently updated.
API requests are limited to one call per user every three seconds, except for the following:
- posts/all - once every five minutes
- posts/recent - once every minute
Some more comments:
1. I think calling 4 requests in 1 hour does not burden server. Each API request is finished in less 1 seconds.
2. Bookmark in pinboard.in is updated only by me, so I know the bookmark is up-to date or not already. Most of time, I got the up-to-date result from cron job. In case there is stale data, I can use 'pbreload' command.
3. I think checking new-data in background can be alternative solution. I want to get most refreshed data without any delay. Without cron job, I need to wait some time until querying is finished. Actually it is short because server is enough fast. But API requests are limited, the next query must be called after 3 seconds.
-
After clicking Edit click on Use Full Editor
Thanks a lot.
-
alfred-pinboard ver2 has been released. http://www.alfredforum.com/topic/4426-alfred-pinboard-version-2/
p.s. How can I change the title of topic in alfred forum?
-
- GitHub Page : https://github.com/jmjeong/alfred-extension/tree/master/alfred-pinboard
- Workflow Download : https://raw.githubusercontent.com/jmjeong/alfred-extension/master/alfred-pinboard/pinboard.alfredworkflow
v2.3 (2016-05-20)
- Update Settings for Alfred v3
v2.27
- Fix a bug in debug logging
v2.25
- change Reload threshold time to 1 hour from 12 hours
- Arrange alfred layout
v2.24
- pblog records copy command
- guard code for invalid bookmark data
v2.22
- Launch history command (pblog)
- Sort option : last accessed time (^l)
- '!' is used to sort key too
V2.1 Changelog
- multiple tag search : specify tag group for searching (#)- display last modified time of local cached bookmarks- display host name only in main list- display tag information in main list too- update the number of entries in the history list after searching- display untagged bookmarks in tag list- support sort option : title ascending(`^a`), title descending(`^z`), time ascending(`^d`), time descending(default)Yet another alfred-pinboard workflow. It provides INSTANT pinboard search and the following function.
- search pinboard (pba) - supports various search condition such as or(|), and( ), and not(-)
- search tag (pbtag)
- search pinboard memo (pbmemo)
- show starred bookmark (pbs)
browse and search history (pbhis)
goto or delete the searched bookmark
- copy url of the searched bookmark
- send url to pocket
- mark or unmark the favorite bookmark
Installation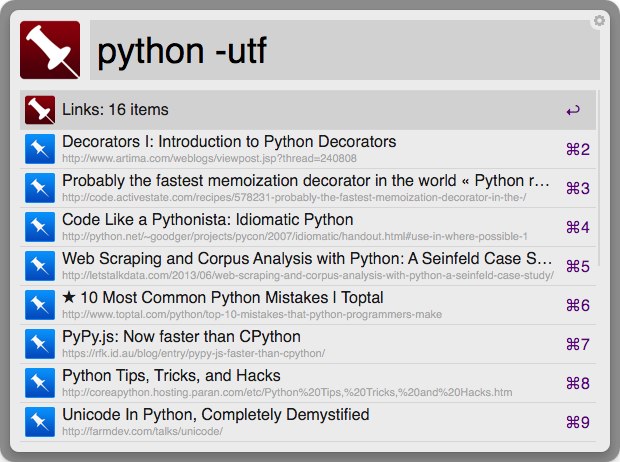
- Download and Install alfred-pinboard Workflow
- You need to set short-key manually
- pbauth username:TOKEN <- set access token
- Get it from https://pinboard.in/settings/password
- pbreload - loads latest bookmarks and memo from pinboard.in
- search with pba, pbtag, pbmemo command
- (optional) pbauthpocket
- needed only if you want to send URL to pocket
- (optional) install cron job : for faster searching without pbreload
- download it from pinboard-download.py
- chmod a+x pinboard-download.py
-
register script in crontab using crontab -e
*/15 * * * * /path/to/pinboard-download.py > /dev/null 2>&1
- pba query : search query from description and link and tags
- pbnote query : search query from pinboard notes
- pbu query : search query from description(title) in unread list
- pbl query : search query from link
- pbs query : search query from starred bookmarks
pbtag query : search tag list. You can autocomplete it by pressing ‘tab’
pbhis : show search history
pbreload : loads latest bookmarks from pinboard.in
pbauth username:token : Set pinboard authentication token (optional)
- pbauthpocket : Pocket authentication (optional)
- - before search word stands for not ex) -program
- stands for and query ex) python alfred
- | stands for or query ex) python|alfred
- and query is evaluated first, than or query is evaluated
You need to set it manually because of alfred restriction
- ctl-shift-cmd-p : launch pba
- ctl-shift-cmd-c : launch pbtag
- ctl-shift-cmd-n : launch pbnote
- ctl-shift-cmd-s : launch pbs
- ctl-shift-cmd-h : launch pbhis
- enter to open the selected url in the browser
- tab to expand in pbtag command
- Hold cmd while selecting a bookmark to copy it’s url to clipboard
- Hold alt while selecting to delete a bookmark from your pinboard
- Hold ctrl while selecting a bookmark to mark or unmark it
- Hold shift while selecting to send URL to pocket. You need to set auth_token using
pbauthpocket
- help
Search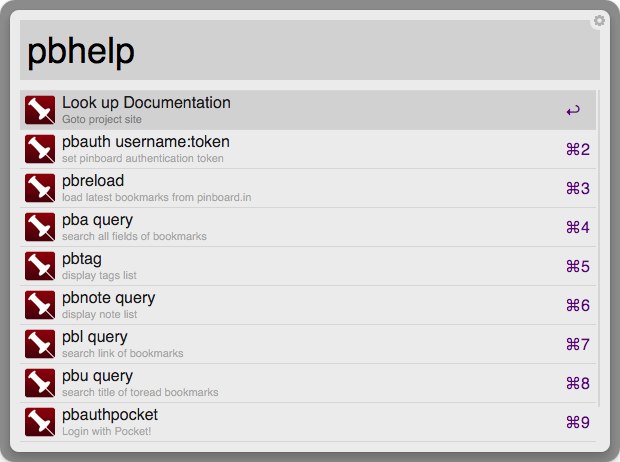
Tag Browse
Tag Search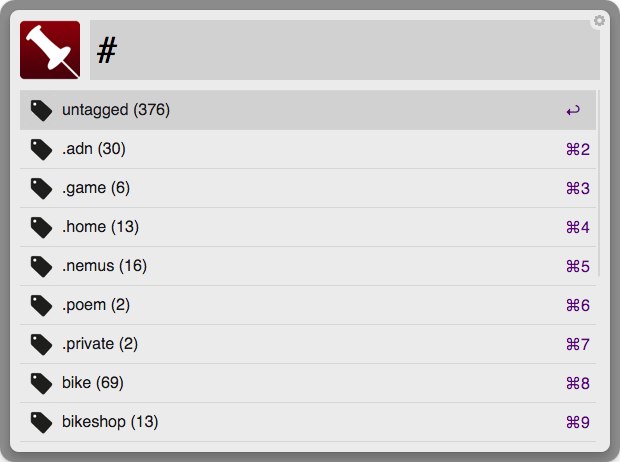
Starred Bookmark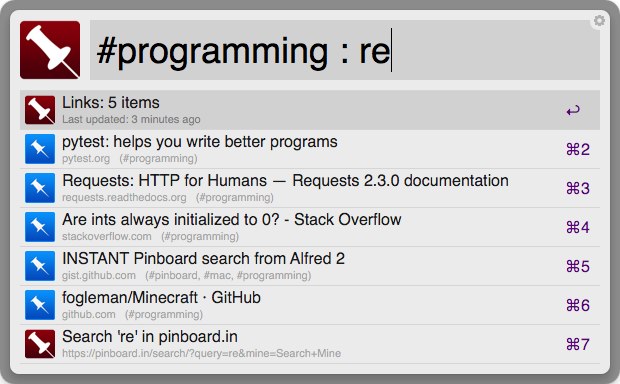
Search History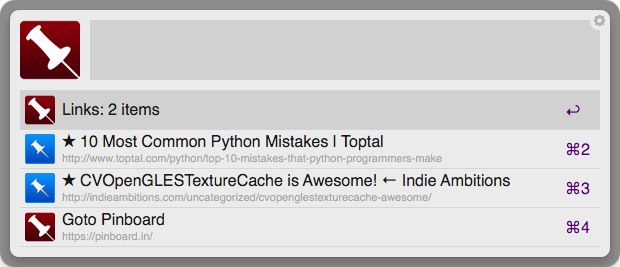
-
Working 100% for me, too. Glad to see the debugger stays open when a workflow is changed, too.
Nice one.
deanishe,
Thank you again for your valuable comments and feedback.
-
Andrew,
v2.3(264) version seems to solve all of issues about xml parsing error. It runs flawlessly with test set.
Thanks. I am happy with this release.
Jaemok
-
Your explanation makes sense to me. It explains why alfred throw parsing error irregularly.
I am looking forward to pre-release. Thanks deanishe and Andrew.
-
I think the biggest clue is the fact that the logged out XML doesn't start correctly (i.e. you don't see <?xml version="1.0" encoding="utf-8"?><items> at the start), so I'm going to investigate if there is an issue why the output from e.g. the Bash script isn't making it back into Alfred to be parsed.
I see the <?xml version "1.0" encoding="utf-8"?><items> at the start line in my debug console.
.jpg)
You can download test4 script from http://cl.ly/0m1r1G14003e/test4.alfredworkflow
-
Your 'test4' bash workflow works perfectly in Alfred for me.
Nope. It doesn't work perfectly. There is 418 items in test4 output xml. It displays only 12 items.
Please see debug console of test4 workflow.
-
NSXMLParser is fine with large data files, and 120 kB is very small. It's used by millions of people, so the chances are that the error (and solution) is in your code.I agree that NSXMLParser is used by millions of people. But I am convinced that the one in alfredapp produces errors with some valid xml. I made another test workflow to test validity of xml output http://cl.ly/0m1r1G14003e. It is bash script to produces xml output, which is validated by http://validator.w3.org/check?uri=http%3A%2F%2Fs.jmjeong.com%2Faa.xml&charset=%28detect+automatically%29&doctype=Inline&ss=1&group=0&user-agent=W3C_Validator%2F1.3+http%3A%2F%2Fvalidator.w3.org%2FservicesAlfredapp produces ERROR: [ERROR: alfred.workflow.input.scriptfilter] XML Parse Error 'The operation couldn’t be completed. (NSXMLParserErrorDomain error 76.)'. Row 1, Col 3225: 'Opening and ending tag mismatch: title line 0 and item' in XML:Ampersands in URLs work just fine for me.
I know I can add '&' in args part in xml, but alfred.py changes '&' into '&' to validate xml automatically. I should change alfred.py file to produce '&'.
Also, the code/workflow on GitHub doesn't appear to be the same code you're using: alfred.py is still the old version.The code is in test-branch
-
I don't escape anything in python, and I use the new alfred-py file. But error is the same.
-
I changed output to 'NFD' normalisation, and tested it more. The frequency of the error is low, but the error happens again anyway.
I can't help concluding that NSXMLParser in alfred app is not good for parsing the large xml data(120K).
The error code is somewhat random. Actually there is no '<' in attributes values in XML.
[ERROR: alfred.workflow.input.scriptfilter] XML Parse Error 'The operation couldn’t be completed. (NSXMLParserErrorDomain error 38.)'. Row 1, Col 5354: 'Unescaped '<' not allowed in attributes values' in XML:
I hope the next version of alfredapp supports json format also for better compatibility.
Another issue:
In alfred-pinboard, I pass '&' for args field to open URL in browser. But I must escape '&' to '&' in xml, and the page does not open correctly in browser.
I could find another workaround for it. But I think json format is more flexible.
-
Hi, I was wondering if anyone had any experience in the area of non-latin characters in Alfred, specifically Korean.
So when I put in 려 into the terminal and feed it into a python program like
python script.py 려
I print out the unicode of the character and get:
려 == '\xeb\xa0\xa4'
Yet when I put 려 into Alfred with the query variable:
python script.py "{query}"
I get:
ᄅ ᅧ == '\xe1\x84\x85\xe1\x85\xa7'
This second output is actually two characters, or the two characters that make up the single character.
Does anyone know how I can force Alfred to return the first version of the character?
-
Thanks for posting the code. I've pinned down the problem (I think). You were on the right track with the Unicode normalisation you commented out.
If you use NFD normalisation (the OS X default) instead of NFC (the Python default), everything works just fine. Note, you're using an older version of alfred.py. It has since been updated to use NFD normalisation (this ensures that command-line arguments match filepaths retrieved from the OS X filesystem).
content = unicodedata.normalize('NFD', content)Thanks for your valuable comment again.
Where can I get the newer version of alfred.py?
I will convert the output of alfred-pinboard to 'NFD' normalization and try to use it some more time.
I think it takes some time to determine if it is solved or not, because every single change of output affects xml parsing result of alfredapp.
-
That is starting to look like an error on Alfred's side of things (the XML validates elsewhere). I've had problems myself in the past with Alfred rejecting valid XML.
Could you possibly post the code that generates the XML?
At any rate, adding a space to the beginning of the output seems to fix the problem, so do that.
alfred-pinboard workflow is in https://github.com/jmjeong/alfred-extension/tree/master/pinboard
I think adding a space to the beginning of the output is not the solution, because sometimes that output produces error and the output without space does well. I feel awkward that the result of xml parsing is random.
-
I made three simple workflows to test this problem.To isolate xml error from other unidentified encoding issue, I make some simple script to display xml output. Test workflow link is http://cl.ly/3D3y1b0N2S0X'test1' script displays error.[ERROR: alfred.workflow.input.scriptfilter] XML Parse Error 'The operation couldn’t be completed. (NSXMLParserErrorDomain error 5.)'. Row 1, Col 189: 'Extra content at the end of the document' in XML:'test2' script is good. 'test2' add only one white space in the first line.'test3' script is good. In 'test3', I added space between "</title>" and "<subtitle>"</title> <subtitle>This symptom is somewhat random. Actually most of times it is ok, but sometimes it displays error.Any comments are highly appreciated.

alfred-pinboard version2.3 (alfred3 support)
in Share your Workflows
Posted
v2.2 (2014-06-20)